
How does a strong data science team help businesses be successful?
“At InveniAI, we are trying to derisk the entire drug discovery process as much as possible. Especially for Pharma companies who compete with the giants in the industry and their massive in-house R&D budgets. Our ML products provide a big advantage for the industry.”
Business objectives
InveniAI is leading the development of ML solutions to accelerate drug discovery and development. AlphaMeld, their flagship ML product, is sought after by leading pharmaceutical companies worldwide. To date, they have impacted around 150 biopharma industry collaborations through their offering. A vital part of InveniAI’s success is their data science team’s commitment to creating valuable ML products and consistently improving their models.
Role of the data science team
The data science team develops ML product offerings that are valuable for clients. More importantly, the team ensures the ML products remain valuable. Consistent innovation is pivotal.
For this phase, the objective was to launch the next version of AlphaMeld which significantly expanded its scope and performance. The new ML models would process much larger (medical research) data sets and complex relationships. The testable hypotheses generated would give the clients a considerable edge in terms of R&D.
The challenge for data science leaders
Practically speaking, data science directors have to be great at balancing speed and cost.
- Optimize the costs too much and the model development cycle will be too slow. They would lose to competition that launches faster and grabs the market share. Their product would be cost-efficient but there are no clients left to sell to.
- Chase after model development speed and costs would skyrocket. The final product turns out too expensive for clients or the businesses sell it at a loss. The model is developed fastest but the business turns unprofitable.

ML product development is complex and prolonged. It takes a combination of expertise in NPD, ML and business domains to innovate the right way, within costs and in time.
How to manage the complexity of ML product innovation?
An ML product requires hundreds of decisions, each with a myriad of dependencies, risks, cost implications and more. The first step to taming the complexity begins with having criteria for decisions – before jumping into making the decisions. A good project plan goes a long way.
Project plan snippet
InveniAI’s ML product development was divided into 5 key stages:
- Manual training
- Model building
- Testing models
- Re-training models
- Ops Automation
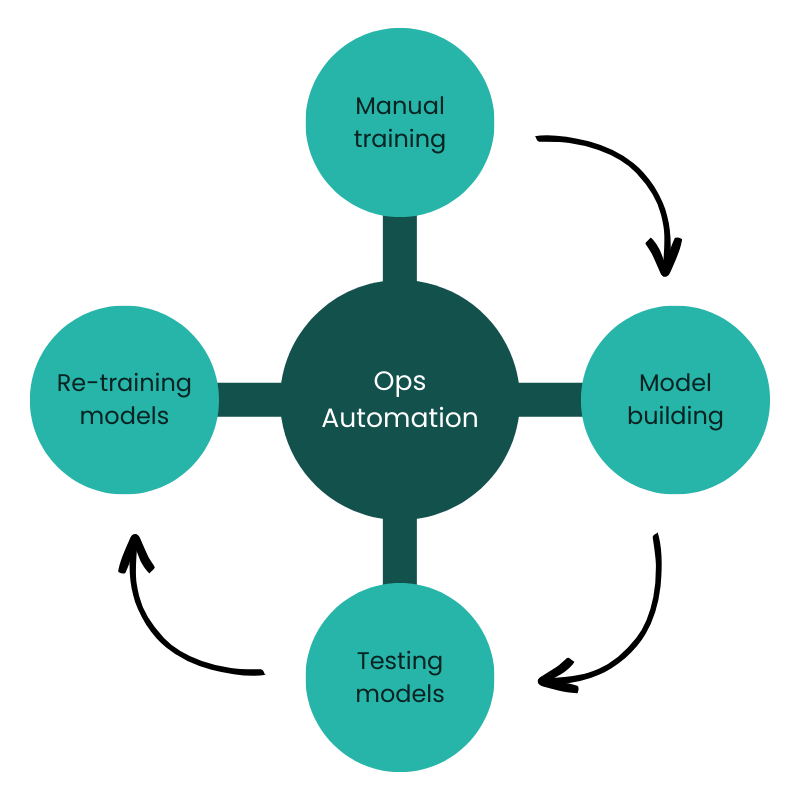
The faster these 5 stages were set up, the faster the team could do model development and experimentation. To be fast, the right way, Dr. Sanatan collapsed the complexity of decisions into key criteria.
You might notice the default option for Ops was automation. ML models are resource-intensive. Manual DevOps was never a viable option for speed.
“If we want to run it on all the data that we plan to have, for eg a billion sentences, starting machines manually, even the bigger machines are not going to solve the problems. It would take years. And you would need a couple of hundred machines to bring the time down to months. You don’t do that scale, manually. And we wanted a Kubernetes system that can handle even 1000 machines”
Decision criteria
The key decision criteria for Dr. Sanatan were as follows:
- What components are to be developed in-house?
- What components are to be purchased?
At the planning phase, internal development vs. purchase historically had a disproportionally large impact on the cost and speed of an undertaking. Each of the 5 stages was separately evaluated on the 2 key decision criteria.
Question:
Just two criteria for such a complex project?
Answer:
Because it was a complex project, it was important to keep the criteria manageable and not get lost in the minutia of decisions. It was about identifying the right criteria rather than having a large list that becomes impossible to track. The right criteria, were informed by experience.
Structured decision-making made the execution smooth. And as we know, with strategic initiatives, smoothly run projects are profitable.
Next steps:
Planning and execution together made InveniAI’s ML product development, successful. We have covered the planning strategy, and the remainder of the case study showcases execution by focusing on stage 5 i.e. Ops automation.
What is a step-by-step plan for Ops automation for ML products?
There were 3 key steps
- To buy or to build Ops automation?
- What are the options available?
- What is the process for assessing these options?
Buy or build ops automation?
“I don’t want to give too much of the DevOps-related work to my subordinates. Let a K8s platform take care of these things. Let me and my team just focus on our work”
Dr. Sanatan had a key principle based on his extensive experience
Ensure data scientists focus completely on core product excellence. No distractions.
Question:
What happens if ‘focus‘ was not a primary principle?
Answer:
Tasks that can be done in-house DO NOT mean tasks that should be.
1. Effort and time spent on non-core is effort and time taken away from core product – it keeps slowing down product development.
2. Leadership is spread thin by managing many teams.
3. Increases risk of competition overtaking them.
4. Diluted focus hurts overall business. An undistracted team is a powerful force. Don’t let non-core tasks distract the team.
“We are already working on the next version of AlphaMeld. All our projects are running smoothly.”
To buy or build a DevOps pipeline? Let’s compare both options.
- Build DevOps automation in-house
- For core-ML business, DevOps is a non-core task.
- Needs hiring, training, and managing a non-core team.
- Requires high investment in time, effort and money.
- Core Tasks are delayed until it is built.
- High investment, low speed and dilutes focus from core product.
- Buy a DevOps automation platform
- Stage 5 set-up is ready and the team can focus on other stages.
- Achieved with the existing team.
- Subscription fees only. Manageable budgets.
- ML product setup and development without delay.
- A monthly fee, immediate availability, and full focus on the core product.
“I didn’t consider hiring and setting up a DevOps team. Never part of the plan.”
For non-core tasks, ‘Buy’ was the best way to deliver on speed and cost. It ensured the team focused on core product excellence.
How do I shortlist options and components for ops automation?
The Kubernetes ecosystem has developed extensively in the past 3 years. For every function, there are multiple options.
Hence before jumping into buying products, Dr. Sanatan first identified the key performance parameters for their DevOps automation platform.
- Speed: The product should have all the downstream automation i.e. cluster creation, environment setup, deployment, alerts etc. The data science team shouldn’t have to wait to test their models, ever.
- Scale: Ability to process a billion data points efficiently. Ability to scale up to 1000 machines and scale down within minutes. (Few other specifications that are not divulged to protect confidentiality)
- Focus, No distractions: The product should automate to the extent that the Data Science team can self-service. The team should not be pulled into DevOps maintenance or fire-fighting.
In a way, the ideal product for DevOps mirrored InveniAI’s commitment to the pharma industry i.e. deliver on scale and speed. This was baked into every aspect of InveniAI.
Considering these parameters, any partial implementations were immediately off the table.
For example, something like the AWS code pipeline would require further tooling with components for monitoring, alerting, image scanning etc. It would require going through the entire decision process for each component of K8s automation.
It would also require further hiring to maintain the integrations, upgrade each component when new releases happen, and undertake fire-fighting.
It would not be an optimal solution for speed, or focus. Hence, the correct choice was to buy a fully developed K8s platform.
“I don’t want to give too much of the DevOps related work to my subordinates. Let a K8s platform take care of these things. Let me and my team just focus on our work.”
How to assess the shortlisted options, What’s the SoP?
The assessment would be made on the key parameters identified so far i.e. balancing cost/speed along with the 3 factors earlier section defined for DevOps specifically.
- Speed (of use in day-to-day DevOps)
- Scale
- Focus
- Speed (of installation)
- Cost
Why spend effort on a pilot test?
- Compare the claims of the product with actual performance.
- Test out smaller details that emerge only during execution.
- Team and stakeholders gain confidence when execution is witnessed.
- If passed, the transition to full deployment would be easy and time-saving.
The assessment would be based on actual performance, rather than claims. Hence, a pilot test was the best approach.
Question:
How would you compare DevOps automation with MLOps options?
Answer:
I have looked into MLOps offerings, there are new ones coming up every year. One immediate difference is that if I go with MLOps, it would be a partial solution. For example, We have client-facing dashboards that pull up data and run queries. These applications can be deployed and managed easily with DevOps. If we did pure MLOps, we would still have to do extra work to set up non-ML automation. Plus we have the flexibility to pick and choose ML stack and still do the Ops automation this way. We know our ML.
To Recap / TLDR:
InveniAI had a business goal to develop the next generation of its flagship ML product. Dr. Sanatan, who leads the division, identified 5 stages for this project. For stage 5 i.e. DevOps automation on k8s, must deliver on speed, scale, focus and cost. The successful approach was to buy a fully developed platform.
The next section of the case study will discuss InveniAI’s evaluation of the Castor platform and the impact of the partnership.
Question:
Dr. Sanatan, were you not worried about depending on some other company for this?
Answer:
I am a control freak. And I am a huge fan of outsourcing. They are not at odds. Outsourcing, done right, reduces risk and keeps you in control.
If we don’t outsource, we would need a DevOps team. Setting up a seperate team is not cheap. It would require a lot of my time as well, to hire, train and guide them day to day. That would turn into a huge distraction for me, the core data science team and the project. If you know that there is a process that needs to be built, you should give it to somebody who is an expert at that, whose core focus is that. Unlike when developed in-house, you can easily change partners when it stops working.
Outsourcing DevOps, counterintuitively, gave more control to InveniAI.
What does Ops automation look like when done with Castor?
“Castor was right there. With everything ready. We immediately tested it out.”
What was Castor assessed on?
“The scaling part was the problem I gave at the start. Castor’s team easily came back with a configuration that solved our need. We tested with a small batch of data and on our intermediate model. It quickly scaled to process a million sentences, without a hitch. The infrastructure costs for our larger intermediate model were now at the same cost as our older model.”
To assess Castor, Dr. Sanatan identified scaling as the objective. Having a clear objective would help the InveniAI team test Castor under different conditions.
Conditions tested using an intermediate model i.e. specific to speed, scale & other key parameters
- How easy is it to spin up a machine, create a new cluster, a new environment? How fast?
- How easy is it to change workflows, autoscaling rules, and provisioning? How fast?
- Is it reliable? Or is there a variance in quality?
- Repeat the 3-step check for various scales. 5 machines workload. 10 machines. 30 machines. 50 machines.
- Is Castor able to optimise and provide a solution if the performance dips at a certain scale?
How did Castor perform in the pilot?
Castor’s team did the onboarding process which included configuration and installation, along with consulting hours to optimize as testing progressed.
- The Castor platform allowed for cluster creation with 2 clicks. Environment setups and workflows in a few clicks if it was a new configuration, and 2 clicks if replicating existing configurations.
- Each repeat task needed no longer than 15 minutes of the data scientist’s time, at maximum.
- The clusters were deployed every time, reliably and automatically. Same with environment setup, workflows, access controls etc.
- Castor supported the different levels of scaling tested.
- Castor was able to work with the team and provide optimization solutions. For example, Castor & InveniAI worked to identify (together) and redesign (InveniAI) parts of the ML application to take advantage of spot instances during the pilot.
By the end of the pilot testing, InveniAI had a fully automated ops platform on Kubernetes that supported ML product development at scale.
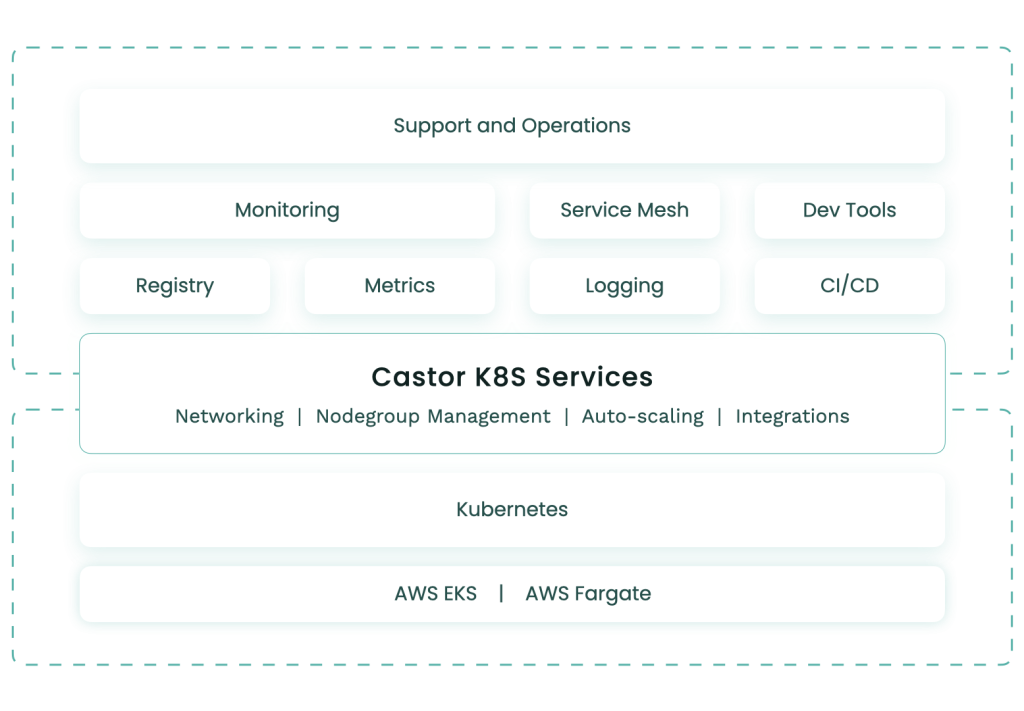
How did AlphaMeld ML model development perform with Castor?
“To see scaling from 0 to 500 machines quickly, it was pretty magical to watch.”
Over the course of the year, InveniAI was able to successfully complete 15 iterations of their ML process and keep it comfortably within budgets. Dr. Sanatan’s decisions led to the perfect balance of speed and cost, releasing a new improved AlphaMeld within a year.
- Speed:
- 15 iterations in a year.
- Deployments under 15 minutes.
- Cluster creation with two clicks.
- Idle machines are identified every 5 minutes.
- Scale:
- Machine peak: 500 machines during model re-training.
- On a typical run: 300 machines scaled up and down automatically.
- Scale achieved within minutes: 50 seconds on fastest, 3 minutes on slowest.
- Focus:
- The improved version was released by one pod expert team within the year.
- AlphaMeld new version was one of the best in the market – provided value better than alternatives. Pharmaceutical clients immediately subscribed/upgraded.
- Cost:
- Just from the costs saved in the first quarter, the Castor subscription for the year was funded.
- The rest of the year’s cost savings ensured the in-house project stayed in the green.
- Cost x Scale optimisation:
- Infrastructure costs were maintained in line with previous budgets, even with scaling beyond previous years.
- Q1: Cost X, Data processed X
- Q4: Cost 1.7X, Data processed 20X
- Infrastructure costs were maintained in line with previous budgets, even with scaling beyond previous years.
“It’s a huge bonus for me and frankly, I don’t even have to think about the cost aspect at all”
Overall InveniAI went through a dozen iterations of the ML Models internally and each of them was supported through Castor, no growth was out of scope. Dr. Sanatan and the Data Science team were able to focus completely and launch a new product within the timelines committed to management. NPD de-risked as much as possible.
With Castor, InveniAI was able to succeed on multiple parameters
1. Data science team did 15 iterations and released an improved version within a year.
2. Scaled from a few machines to 300-500 machines while the costs didn’t even double.
3. No extra budget needed for DevOps team salaries as it was fully self-serviced.
4. The data scientists spent no more than 15 minutes or 4-5 clicks for any DevOps task.
Why was the partnership between InveniAI & Castor a success?
A retrospective of the success
“You’re creating a cluster automatically. And nobody has access to it, from the security point of view it’s very safe and secure. We even moved away from deployment templates to Helm, much easier for our volumes. Basically, everything with Castor is straightforward. We don’t have to think every time or worry about something. Gives me peace of mind.”
- Expertise: Castor the product was secure and reliable. Castor’s team was an expert in the domain. This allowed InveniAI to focus on its core – ML models.
- Flexibility: InveniAI is committed to innovating and improving its models. Castor is designed to be flexible and adapt to a growing application. It never hampered the data science team. They keep running different models with increasing scale, without a hitch.
- Trust: Castor and InveniAI teams treated the partnership as a joint problem-solving exercise. This ensured that even when edge cases emerged, it was solved.
“We are meeting next week for the next area of optimization. We have solved for high volumes. We also did quite a lot of cost optimization like that of a spot instance advice. Now, me and Castor would tackle wasted resources. How much further can we optimize idle machines?”
What’s next for InveniAI – Castor?
Dr.Sanatan and the team are already working on the next version of AlphaMeld. They continue their commitment to consistent improvement. Read more about AlphaMeld here.